
Recently at work I was trying to get our CI/CD system to build the very VM images that it runs on. I've hinted previously at our attempts to automate this, but it was still a "manual" automation - i.e. we had to manually kick off the scripts. If we can get the CI/CD system to run it, then we can just make this a build definition (albeit a very long-running one) like everything else, and automatically run it when somebody make a change to the scripts.
We have two VM definitions at the moment, one is about 70GB and the other is about 85GB. As such, once the build definition is finished, we need to store the build output as 155GB of data in a big ZIP file and upload that to our build artifact storage.
My first attempt was just to see what happened. It turns out the system could ZIP 155GB, but using the default .NET Framework implementation of System.IO.Compression.ZipArchive, it took 10 hours with Optimal compression. After taking only 3-4 hours to build the VMs, that's way too long for an acceptable ZIP time.
I then tried to disable compression by passing the CompressionLevel.NoCompression flag to the code, but it seems that the .NET Framework still passes the data through the Deflate algorithm, and it still takes ages. This seems to be fixed in .NET Core 3.0, but we're still running on .NET Framework, and there are no newer binaries available on NuGet.
I tried an alternative library, SharpZipLib, and it took 20 minutes. Just to see what would happen, I tried zipping it up with 7-Zip, and it took 4 minutes 30 seconds.
Unfortunately I couldn't just use 7-Zip, because I needed the folder names on the filesystem and the folder names in the ZIP to be different, and 7-Zip doesn't seem to support this.
I knew the basics of the ZIP format, so I ended up with a dangerous idea - why don't I just write my own fast ZIP writer? How hard can it be?
The ZIP Format
In theory, the ZIP format is fairly straightforward.
- A ZIP file contains a set of entries. These have a Local File Header, followed by the (compressed) file data. If your compression type is "store", this is the raw uncompressed file data.
- Towards the end of a ZIP file (usually) is a Central Directory. This acts as an index, containing information about each file, as well as where to find the Local File Header for it.
- At the very very end of the ZIP file is an End of Central Directory Record. This tells you where to find the Central Directory Record.
That seems easy enough, so armed with the ZIP specification, I sat out to write my own writer. Unfortunately there are a few hiccups in the spec:
- The field size for "compressed bytes" and "uncompressed bytes" are 4 bytes wide.
- The field size for "offset of local file header" and "offset of Central Directory Record" are 4-bytes wide.
- It didn't actually affect me, but the field size for "number of files in this ZIP" is 2 bytes wide.
This is quite problematic. The maximum value that you can fit in 4 bytes is 4294967295, which as a number of bytes is just one byte short of 4GB. The maximum value that you can fit in 2 bytes is 65535, so you can't have more than that many files in a ZIP file.
Or can you? I knew 7-Zip could create my 155GB ZIP file, so how did it do it?
ZIP64 To The Rescue!
There's this extremely useful section in the specification:
4.3.9.2: When compressing files, compressed and uncompressed sizes SHOULD be stored in ZIP64 format (as 8 byte values) when a file's size exceeds 0xFFFFFFFF. However ZIP64 format MAY be used regardless of the size of a file. When extracting, if the zip64 extended information extra field is present for the file the compressed and uncompressed sizes will be 8 byte values.
This seems very useful. This is the good stuff. This is exactly what I need.
If I can store my sizes as 8-byte values, that means I can store files up to 17179869184 GB, or 16 Exabytes!
Similarly, there's another extremely useful section:
4.4.1.4: If one of the fields in the end of central directory record is too small to hold required data, the field SHOULD be set to -1 (0xFFFF or 0xFFFFFFFF) and the ZIP64 format record SHOULD be created.
There are also references to something called the "ZIP64 End of Central Directory Locator".
Unfortunately for me, none of the ZIP64 stuff is very well documented. I had to look at other implementations and do byte-by-byte comparisons with my code's output and 7-Zip's in order to figure out what exactly was needed.
How ZIP64 Works
Here's the birds-eye view of how ZIP64 works:
A Local File Header or Central Directory Record can have what is called an "extra field" in the spec. This is extra data that is not defined by the core spec. Some extensions are defined by newer versions of the spec, others can be completely third-party. Technically you could invent your own field and store a meme for each file, or a URL, or another ZIP, or some secret stenanographically stored data.
Each extra field starts off with a header - two bytes for the field ID, and two bytes for the field size. Also, the size of all the extra data for a record is two bytes, so you can't have more than 64K of extra fields.
The ZIP64 extra field has a field ID of 0x0001, and then the size of your data. This is variable, depending on which data you need.
For a Local File Header or a Central Directory Record:
- If the uncompressed size of the file is greater than
0xFFFFFFFF, then you set the bytes containing the uncompressed file size to0xFFFFFFFFand the subsequent 8 bytes of the extra field data are the actual uncompressed size. - If the compressed size of the file is greater than
0xFFFFFFFF, then you set the bytes containing the compressed file size to0xFFFFFFFFand the subsequent 8 bytes of the extra field data are the actual compressed size.
For the Central Directory Record only:
- If the offset of the Local File Header is greater than
0xFFFFFFFF, then you set the bytes containing the offset to0xFFFFFFFFand the subsequent 8 bytes of the extra field data are the actual offset.
In all of these cases, you can just use ZIP64 even if those sizes or offsets are less than 0xFFFFFFFF by doing the same thing. ZIP64 isn't restricted to large values only, you can force your code to use it to aid in debugging etc. even for small values.
On the Central Directory Record there's also an extra field in the ZIP64 record for the Disk Start Number, i.e. if you have a large ZIP file that's split across multiple files, but I don't think anybody has actually used that since floppy disks went out of fashion. It's also irrelevant to my use-case, so I just skipped it.
Also, if you're using ZIP64, the tool opening it has to understand version 4.5 of the ZIP spec. This is done by setting the "minimum version to open" field in the file metadata to 45, or 0x002D.
Visualizing ZIP64
I find this sort of thing generally works better with an example.
Let's say that we have a ZIP file, with no compression, and it contains one entry. The entry has a name "README.txt" and the file data is "Hello, World!".
This is what a regular ZIP would look like that matches this description:
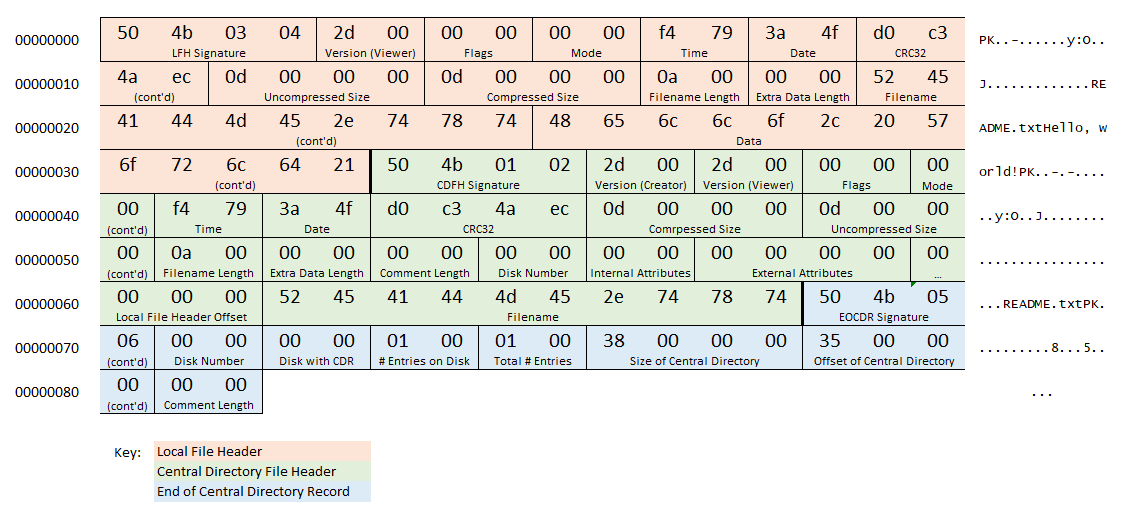
This is what the equivalent ZIP file would look like, using ZIP64 extensions. All the new ZIP64 sections have light text on a dark background.

When a ZIP reader sees 0xFFFF/ 0xFFFFFFFF in the fields for the End of Central Directory Record, it just keeps reading further back in the file until it finds the ZIP64 End of Central Directory Locator. If then uses that to find the actual, 64-bit-aware ZIP64 End of Central Directory Record.
Did it work?
So, after all this effort understanding the ZIP spec and writing my own 'compressor'... my code was only just a little bit faster than SharpZipLib, and still took about 4x as long as 7-Zip.
After doing some profiling with dotTrace, I could quickly observe that most of my CPU time was being spent in the implementation of the CRC32 algorithm.
I went looking for a faster CRC32 implementation, found one, and my solution now took about 5 minutes to package my 155GB of data. It's a touch slower than 7-Zip, but still drastically faster than the original 10+ hours.
Conclusion
All in all, this was a pretty fun challenge. I managed to achieve a roughly 60x optimization, meet the business requirement, and dig deep into how a ZIP file works along the way.
I also learned that the file last modified timestamp in a ZIP entry is only accurate to every two seconds, and that it only goes up to the year 2107. Considering that everybody loves building on top of ZIP files - iOS IPA files, Android APK files, etc. - I can only hope that in the next 88 years we invent a better packaging format that has more than 4 bytes allocated for a timestamp. Or, perhaps one day we could just reset the epoch.
If there's one thing I don't like about the ZIP format, it's that it's designed to be easy to append new entries to. This is why the Central Directory and End of Central Directory Record goes at the very end of the file.
This is great if that's what you actually want to do, but in modern computing most ZIP files don't change. You zip stuff somewhere once, unzip it at the other end, and that's about it. If, on the other hand, you want to be efficient and start unzipping the file as it comes across the network, you can't really do that. All the information about the entries is at the very end, so you effectively have to download the entire file before you can accurately parse any of it.
Technically you could start interpreting the Local File Headers, but the ZIP spec does leave room for things like padding, or completely unrelated data (steganography, anyone?), so that's hardly a foolproof solution.
Maybe we should just all use TAR instead. 😅

