
When I first got into running my own servers, I liked to host just about anything I could (and would actually use), which became a bit of a pain as you have to manage the operating system, system libraries, various software runtimes, create /etc/init.d scripts, assemble your own Nginx config files and get all the proxy_pass directives right, and also figure out how on earth to keep track of all of it.
Things have come a long way since then with Infrastructure-As-Code and all sorts of tooling, but for me I think the biggest improvement has been Docker and the base layers of Kubernetes, which effectively take software and all of its complex dependencies and turn it into an appliance. Bring your own kernel, network connection, and persistent storage, and boom you now have some working software. Hosting your own software has become a lot easier and a lot more reliable since the days of my first Linux VPS.
This week I decided to try my hand at self-hosting a Git server with Continuous Integration and Continuous Deployment. I don't have anything fundamentally against the big players like GitHub and GitLab, but I'd like to have a bit more control over my stack for personal projects and not rely on the graces of a megacorp. Also, I wanted to see what had changed since last time I tried this, back in the days when Redmine was somewhat popular.
I already had a VPS that wasn't doing much, and a home NUC that was similarly spending most of its time fairly idle, so this would be a good use of those spare resources. I also wanted to do this on a tight budget, without dropping tens or hundreds of dollars more per month on cloud resources.
My VPS actually already runs a Microk8s stack, which makes a few things much simpler, such as the Kubernetes Ingress mapping incoming HTTP(S) requests to their respective application without me having to manually maintain Nginx config files, and I also use cert-manager to automatically provision and renew SSL/TLS certificates from Let's Encrypt.
So, to pull off self-hosted Git/CI/CD, I would need a few new key components.
Storage
All of my code, associated workflow systems (issue tracking, pull requests), supporting systems (user management), and all of the code itself would have to live somwhere. With a regular VPS backup schedule, local filesystem storage is probably fine. I don't have enough personal activity to necessitate scaling out to two or more servers with a load balancer in front.
Whatever Git and CI/CD system I chose would probably also need a database server, and for open-source solutions that generally boils down to either MySQL or Postgres. Personally I prefer Postgres, and again, it can just keep its data on the local hard disk as I don't need a massive scale-out / high-availability solution here.
Git Server
I first looked at GitLab, which is basically the primary open-source competitor to GitHub these days and offers a free tier that you can host yourself, but it seemed to be pretty heavy. They offer it as a giant "Omnibus" set of packages, a big Docker container, or as Helm chart or an Operator for Kubernetes. The docs were pretty off-putting for a baby operation as their lowest suggested tier is 0-1000 users, and I am just 1 simple user, and it seemed like it would be demanding a lot more CPU and memory than I wanted to devote to this.
I poked around a little bit more and settled on Gitea, an open-source Git host that I've toyed around with before. It stores its data in a mix of filesystem storage (some of that can be offloaded to S3-compatible storage) and a relational database, either SQLite3, MySQL, or Postgres, so I went with Postgres. I followed the docs for Docker but adapted them to turn it into a Kubernetes YAML file instead, and ignored the complexity of forwarding SSH ports by simply disabling SSH in the out-of-box setup wizard (set the SSH port number to 0).
My Kubernetes Deployment for it looks something like this:
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: gitea
name: gitea
spec:
replicas: 1
selector:
matchLabels:
service: gitea
template:
metadata:
labels:
service: gitea
spec:
containers:
- name: gitea
image: gitea/gitea:1.16.5
env:
- name: USER_UID
value: '1000'
- name: USER_GID
value: '1000'
- name: GITEA__database__DB_TYPE
value: postgres
- name: GITEA__database__HOST
value: postgres.data # The Postgres container is named "postgres" but is under the "data" namespace.
- name: GITEA__database__USER
value: gitea
- name: GITEA__database__PASSWD
valueFrom:
secretKeyRef:
name: gitea-postgres
key: password
volumeMounts:
- name: data
mountPath: /data
ports:
- name: http
containerPort: 3000
protocol: TCP
volumes:
- name: data
hostPath:
path: /data/gitea # This is the directory on the host where all the data will be stored
type: Directory
In this config we load the Gitea container for version 1.16.5 (the latest as I write this), tell it where to find its database, and tell Kubernetes where to store its data.
I added a matching Service and an Ingress (which automatically took care of SSL/TLS thanks to cert-manager as mentioned above), clicked through the out-of-box setup wizard, and had a blank Git server all ready to go.
The last thing I did was customise the home page and logo, which is well-documented, but their logo generation command make generate-images relies on node-gyp which still doesn't work properly on Apple Silicon (M1), so I had to run this on an x86_64/amd64 machine. Oh well.
I decided to call it Shehakode as a portmanteau of "Shehakol", the blessing in Judaism that one says before drinks such as tea (i.e. Gitea), and "Code"
CI/CD Service
Now that I had a working Git host, I needed a way to trigger automatic builds and deployments.
I had a look at several different solutions, including classics like Jenkins and Buildbot, but eventually settled for trying out a new solution, Drone. It has inbuilt support for Gitea, both for authentication and for the little build-status tags that you can add to commits and Pull Requests when an associated build passes or fails.
Drone comes in two parts: The Drone Server, which processes requests and coordinates the jobs, and the Drone Runners, which are the bits that actually checkout the code and execute build commands.
Even though the docs say:
Please note we strongly recommend installing Drone on a dedicated instance. We do not recommend installing Drone and Gitea on the same machine due to network complications, and we definitely do not recommend installing Drone and Gitea on the same machine using docker-compose.
I thought about it for a bit, then ignored their recommendation and installed Drone into the same Microk8s instance on the same VPS as Gitea.
They have a guide to walk through (linked above) on setting it up, and once again after adapting it from a general Docker install to a Kubernetes configuration, my deployment looked something like this:
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: gitea
name: drone-server
spec:
replicas: 1
selector:
matchLabels:
service: drone-server
template:
metadata:
labels:
service: drone-server
spec:
containers:
- name: drone-server
image: drone/drone:2
env:
- name: DRONE_GITEA_SERVER
value: https:// #redacted
- name: DRONE_GITEA_CLIENT_ID
value: # redacted
- name: DRONE_GITEA_CLIENT_SECRET
valueFrom:
secretKeyRef:
name: drone
key: drone-oauth2-secret
- name: DRONE_RPC_SECRET
valueFrom:
secretKeyRef:
name: drone
key: drone-rpc-secret
- name: DRONE_SERVER_PROTO
value: https
- name: DRONE_SERVER_HOST
value: # redacted
- name: DRONE_DATABASE_DRIVER
value: postgres
- name: DRONE_DATABASE_DATASOURCE
valueFrom:
secretKeyRef:
name: drone
key: connection-string
# One of Drone's own environment variables conflicts with one
# automatically generated by Kubernetes, because we named
# this "drone-server". If we chose a different name then this
# would not have happened.
# https://discourse.drone.io/t/drone-server-changing-ports-protocol/4144/2
- name: DRONE_SERVER_PORT
value: ":80"
volumeMounts:
- name: data
mountPath: /var/lib/drone
ports:
- name: http
containerPort: 80
protocol: TCP
volumes:
- name: data
hostPath:
path: /data/drone-server # This is the directory on the host where all the data will be stored
type: Directory
In this config, we load the Drone container, tell it where to find its database, where to find Gitea, where it is located itself, and where Kubernetes should map its data directory to.
Once I had this up and running I could log into its web interface, activate it for a repository, and once I commited a .drone.yml file, it would queue up CI/CD jobs to run. For a quick hello-world-style test, I created the following CI config:
kind: pipeline
type: docker
name: default
steps:
- name: hello
image: debian:10
commands:
- cat README.txtThis does exactly what it looks like it does - it boots up a debian:10 Docker container and prints the contents of README.txt.
Unfortunately, we haven't yet set up a runner, so this build job will just remain in the Pending state, possibly for eternity? I don't know if there is a timeout for that.
In a change of tune, I set up the runner on a different machine - on the NUC at home. I was a little bit concerned about the security implications of this, as the internet is sending arbitrary commands to a machine on my home network, but I figured I can at least lock down the runner to only process my own repositories.
I set this up using the Docker guide, which is probably good enough for now, but a little bit concerning as it bind-mounts /var/run/docker.sock so that it can create and run its jobs in other Docker containers, but that really gives it the keys to the whole kingdom. There are other runners too, but I didn't want to run the Kubernetes runner as Kubernetes uses quite a bit of CPU, which on home hardware means more noise and heat and power consumption. This is probably good enough for now but I'll probably revisit it soon.
To get this one going I installed Docker (somehow I didn't have it already), then just ran the command from the docs and substituted my own values:
docker run \
--detach \
--volume=/var/run/docker.sock:/var/run/docker.sock \
--env=DRONE_RPC_PROTO=https \
--env=DRONE_RPC_HOST=redacted \
--env=DRONE_RPC_SECRET=redacted \
--env=DRONE_RUNNER_CAPACITY=4 \
--env=DRONE_RUNNER_NAME=my-runner-name \
--restart=always \
--name=drone-runner \
drone/drone-runner-docker:1I took out --publish=3000:3000 as the runner's web interface isn't even enabled unless you set DRONE_UI_USERNAME and DRONE_UI_PASSWORD, and even then I didn't find it particularly useful. If I want to later I can recreate the container with those arguments set and see what's going on, but for now I didn't think it neccesary in the slightest.
After adding that runner, it slurped up my pending jobs and printed the README file to the console!
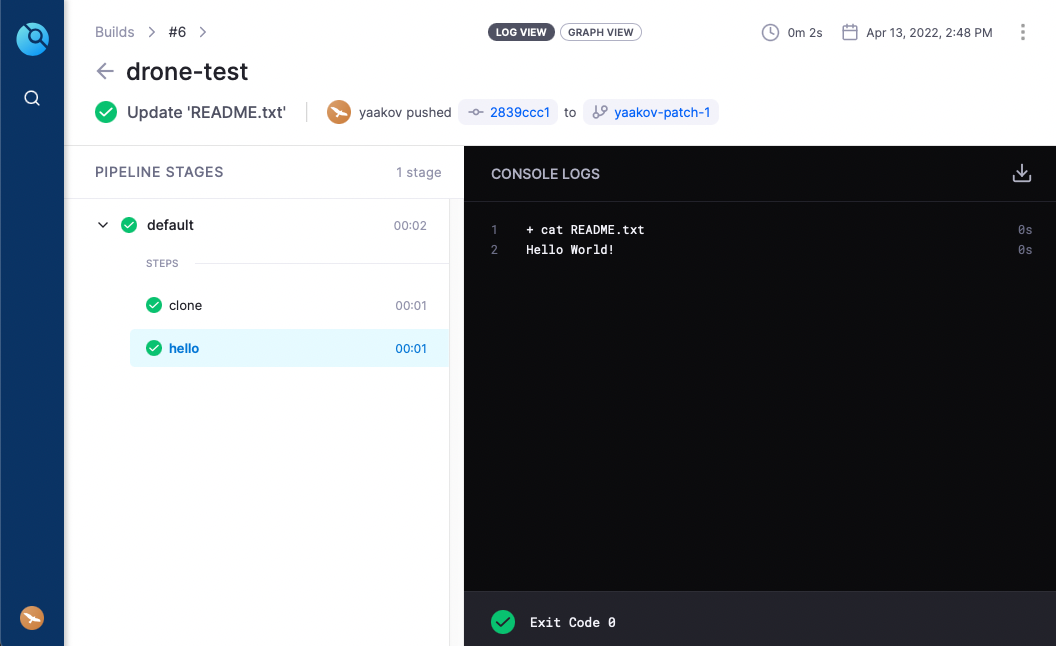
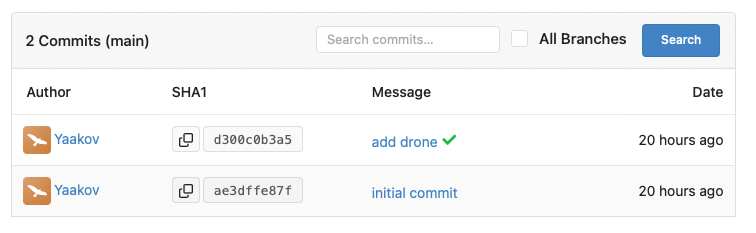
Once this CI job ran, it showed up as a green checkmark on my commit history back over in Gitea, and even links back to the Drone UI.
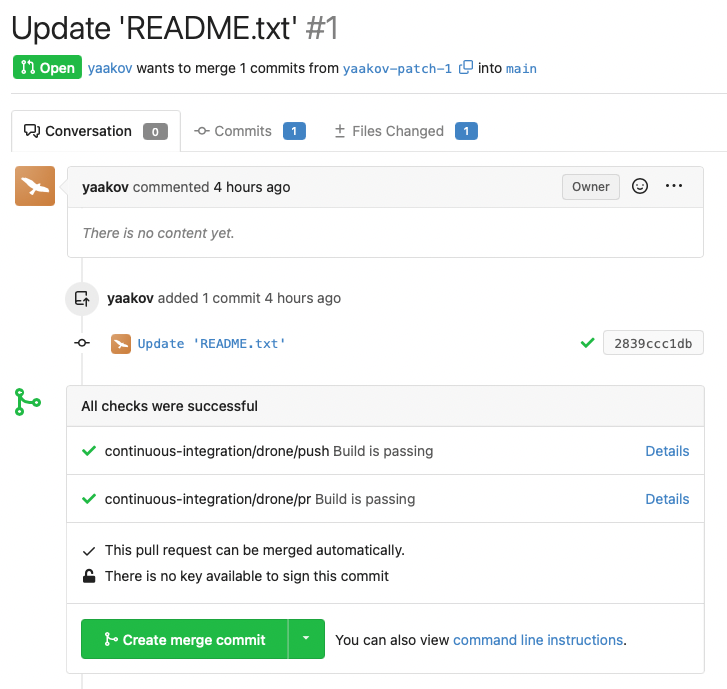
It also shows up on Pull Requests as one might expect.
Conclusion
All in all, that ended up being a lot easier than I expected, and a lot simpler than the last time I poked at something like this for personal use (corporate/commercial use is a completely different story).
By loading up a few appliance-like containers, giving them storage, and telling them how to connect to each-other, I now have a private Git instance on my VPS with builds running on my far over-specced and under-utilized Intel NUC.
It's all fairly lightweight, as when the whole system is idle:
- Postgres uses 0% CPU and 52MB of memory
- Gitea uses 0-2% CPU and 170MB of memory
- Drone Server uses 0% CPU and 11MB of memory
- Drone Runner uses 0% CPU and 8MB of memory
That's just 233MB of memory on the VPS and 8MB of memory on the NUC.
Maybe next I'll pull a Raspberry Pi out of the cupboard and get some builds running on arm64, but for now I'm quite happy with this setup. I just have to remember not to dogfood myself into a circular dependency hole where my GitOps stuff relies on the self-hosted Git installation that it itself defines.

